نتعامل مع الحاسوب باستعمال الأحرف و الأرقام و الرموز التي تعوّدنا عليها سواء بإدخالها عبر لوحة المفاتيح أو عند عرضها في
الشاشة أو الطابعة. يقوم الحاسوب بتخزين كل المعطيات على شكل أعداد صحيحة في النظام الثنائي. ولذلك فمن المهم أن تتفق كافة أجهزة الكمبيوتر على الأرقام التي تمثل فيها الحروف. هذا ما يستدعي استعمال نظام ترميز خاص.
استحدث نظام ASCII للحرف اللاتيني في البداية و الذي يضع لكل حرف، رقم أو رمز إملاء، عدد خاص من 0 إلى 127 . تقسّم كما يلي:
من 0 إلى 31 و و العدد 127 تخصص للرموز الإملائية و بعض أوامر التحكم.
من 32 إلى 126 تخصص للحروف اللاتينية العادية في صيغتها الكبيرة أو الصغيرة كما هو موضح في الجدول التالي.
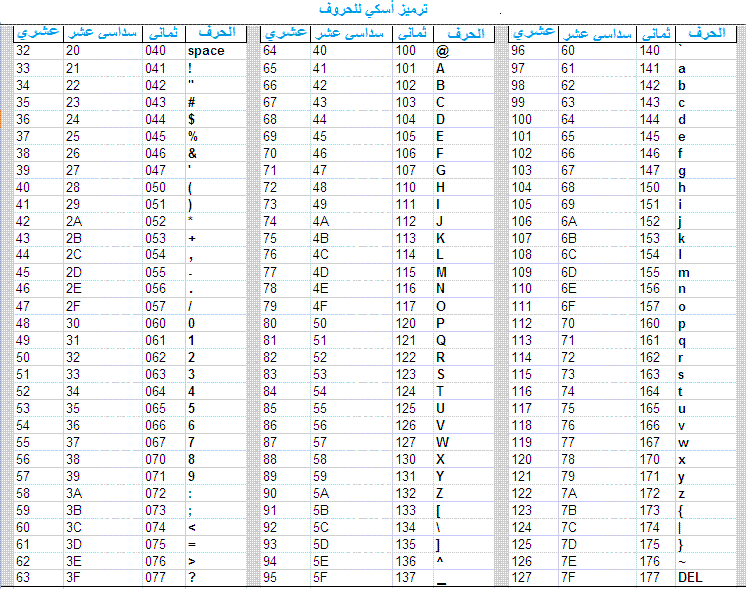
من الجدول السابق نلاحظ ان رمز الحرف A هو 41 و كذلك رمز الزر مسافة space من لوحة المفاتيح هو 20.
فعندما نضغط على المفتاح مسافة فإن لوحة المفاتيح ترسل الرمز 20 أي ما يعادله 0100000 في النظام الثنائي إلى جهاز الحاسوب الذي يرسل نفس الرمز إلى معالج الشاشة و الذي بدوره ينقل المؤشر المرئي إلى اليسار (أو اليمين حسب اللغة) قدر حرف.
نظام أسكي و اللغة العربية
نظام أسكي الأولي يستغل 7 بت من ثمانية فقط. و قد استعملت الرموز من 128 إلى 255 (8 بت) من أجل حروف مختلف اللغات و لكن الأمر لم يكن عمليا. و بعد عدة اجتهادات توصلت عدة منظمات ومؤسسات عربية ودولية إلى اختيار مواصفة قياسية عربية مناسبة للحاسوب. (كما كان الشأن بالنسبة للّغات الأخرى).
انتهى الأمر بالمواصفات إلى سلسلة المعايير ISO 8859، أولها ISO 8859-1 و الذي يعرف باسم latin-1، يمثل فيه الحرف اللاتيني. و بما أن الجدول لا يكفي جميع اللغات فقد قُسّم إلى عدة أجزاء تحظى العربية منها بالتصنيف ISO-8859-6 كما يوضح الجدول التالي.
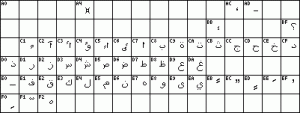
حاليا تم إدخال تعديلات بإنشاء نظام جديد للترميز يتكون من 16بت و يسمى UNICODE و الذي يسمح بتمثيل 65536 حرف من مختلف اللغات بما في ذلك العربية و الصينية و غيرها.
فاليونيكود يحدد لكل محرف عدد فريد بغض النظر عن المنصة، البرنامج أو اللغة.
merci